DataFrame in spark is Immutable in nature. Like the Resilient
Distributed Datasets, the data present in a DataFrame cannot be altered.
- Lazy Evaluation is the key to the remarkable performance offered by the spark. DataFrames in Spark will not throw an output on to the screen unless an action operation is provoked.
- The Distributed Memory technique used to handle data makes them fault tolerant.
- Like Resilient Distributed Datasets, DataFrames in Spark extend the property of Distributed memory model.
- The only way to alter or modify the data in a DataFrame would be by applying Transformations.
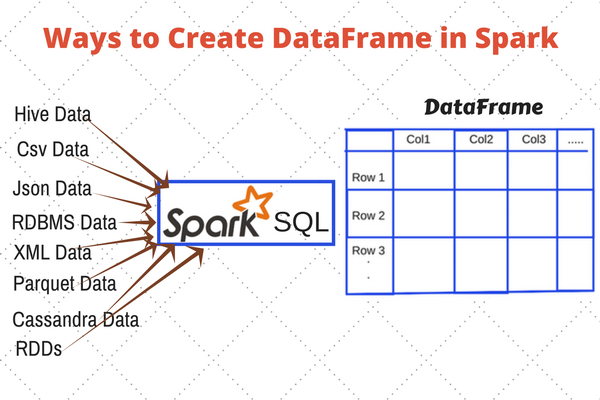
DataFrame can be Created in multiple ways
- From an existing RDD
- From an existing structured data source like HIVE, JSON
- Using Case Class
- Using CreateDataFrame method
- By performing an operation or query on another DataFrame
- By programmatically defining a schema.
DataFrame save Mode
SaveMode.ErrorIfExists :- When saving a DataFrame to a data source, if data already exists, an exception is expected to be thrown.
SaveMode.Append :- When saving a DataFrame to a data source, if data/table already exists, contents of the DataFrame are expected to be appended to existing data.
SaveMode.Overwrite :- Overwrite mode means that when saving a DataFrame to a data source, if data/table already exists, existing data is expected to be overwritten by the contents of the DataFrame.
SaveMode.Ignore:- Ignore mode means that when saving a DataFrame to a data source, if data already exists, the save operation is expected not to save the contents of the DataFrame and not to change the existing data. This is similar to a CREATE TABLE IF NOT EXISTS in SQL.
No comments:
Post a Comment